Vespa 在處理查詢的時候,有預設的 timeout 機制,能夠在時間不夠的時候將既有已經收集到的結果吐出,而不是放棄既有的結果並回覆 504 timeout。這樣的行為其實就是現代的 reactive system 的思維。這裡會簡要地介紹 timeout 的機制 [1],並且提一下最近遇到的實例。
Phased Ranking
在談 timeout 之前,需要粗略地先了解 Vespa 執行搜尋的時候大略有哪些步驟要執行。概略來說,Vespa 的搜尋可以分成 match 和 ranking 兩個步驟,也就是先找出符合條件的 matched documents,再針對這些 documents 做比較複雜的 ranking 運算去決定排序。而一般狀況來說,比較常造成 performance bottleneck 的都是落在 ranking 階段較多。畢竟因為一般狀況很多資料都會被放在記憶體裡,match 階段大半都是記憶體操作,比較不容易慢得太誇張。
接下來會再針對 ranking 階段做一點簡單的介紹,或者也可以參考文件 [2]。
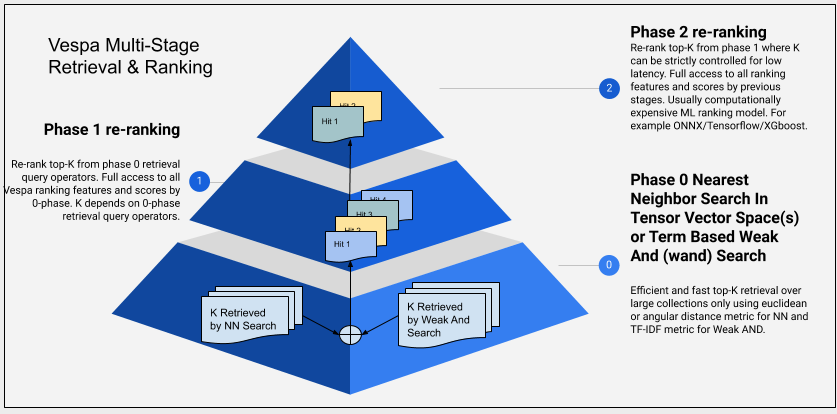
如上圖所示,早期 Vespa 的 ranking 階段被稱為 two-phase ranking,也就是有 phase 1 和 phase 2。不過因為去年 phase 0 的出現,使得現在嚴格來說變成了三個階段。不過概念上其實還是很類似。
在 two-phase ranking 的時候,phase 1(或稱為 first phase)和 phase 2(或稱為 second phase)的目的是要先讓 phase 1 用簡單的運算快速做資料篩選,盡可能留下較少的資料送入 phase 2。而 phase 2 就是最複雜的運算,例如 ML 的運算一般會期待發生在 phase 2。整理來說,就是透過 match 階段篩選出符合條件的 documents,接著在 phase 1 ranking 時用相對簡單的運算,從 matched documents 中挑出 top-K 送入 phase 2,最後在 phase 2 針對這些 top-K 做完較複雜的 ranking 運算,決定最終的排序結果。這就是 two-phase ranking 大致的概念,相當直覺的邏輯。
從 two-phase ranking 演變成 phased ranking 的主要差異是加入了 phase 0,也就是上圖中金字塔最下面的那層。這層存在的目的其實跟 phase 1 是一樣的,只是是在 phase 1 之上,意圖用更加簡單的運算,快速把 matched documents 的數量縮減,以達到讓 phase 1 的運算需要處理的 document 數更少的目的。
關於 phase 0 到底是如何達到這個目的的,這篇就先不描述太多(雖然其實我也沒有很懂原理 XD)。不過需要知道的大方向就是 Vespa 是透過 WAND 演算法或者 NN 來作到的,這兩種作法都可以讓 Vespa 能夠在不需要看過所有的 matched document 的情況下就決定出誰是 top-K。因此理論上能夠比 phase 1 更加輕量。
timeout 與 soft timeout
翻閱 Vespa 的文件 [3-4] 的話,可以注意到 Vespa 有 “timeout” 和 “ranking.softtimeout.*” 這些名字帶有 timeout 的參數。兩者 (?) 在實際使用上是有關聯的。
timeout
timeout 代表的是整體的時間,也就是說從 Vespa 收到 request 一直到回覆搜尋結果為止的整體時間(或者稱為 “預算”,Vespa 在文件中會用預算來形容這個概念)。當 Vespa 在處理 request 時,會隨著處理的進行持續消耗預算(畢竟時間是會一直前進的),當它發現剩餘預算已經幾近耗盡時,就會放棄後續的計算,將現在已經收集到的結果回覆給客戶端。
ranking.softtimeout.*
看到這個參數前面帶著 “ranking” 這個關鍵字,應該可以略為了解它會用在哪裡 XD。這也是為什麼上面會需要先大概了解 Vespa 的運作,因為這個參數就是針對 ranking 階段做的設定。
這個參數主要的用途是用來決定 Vespa 如何分配 timeout 指派的時間(預算)。預設的比例是 0.7,意思是說如果 timeout 設為 1 秒的話,那麼會有 70% 的時間會用在 phase 1 以前、30% 的時間用在 phase 2。
看起來是蠻直觀的,不過有個也很直觀但容易被忘記的細節(hmm…或者可能只有我忘記了 XD)。假設 request 的 timeout 設定為 1 秒,並且有開啟 ranking.softtimeout 時,如果 rank profile 裡只寫了 first-phase 但沒用到 second-phase 的話,實際上 request 總共可用的預算會只有 0.7 秒,而不是 1 秒!這是因為還是會有 0.3 秒被保留給 phase 2,但因為 phase 2 沒有被定義,所以就直接略過了。
撞牆小經驗
上面最後講到的問題,其實就是我們團隊近期撞到的牆。概要是說我們發現 rank profile 裡有一段寫在 first-phase 的邏輯的運算成本比預期的還高不少,所以要把這段邏輯從 first-phase 移到 second-phase,但結果移轉之後測試卻發現搜尋速度反而變慢了,從原本的大約 2 秒變成接近 3 秒(表示為黑人問號)。後來仔細研究後發現,原來因為我們的 timeout 設定為 3 秒,這些 request 本來就會因為花太長時間而撞到 timeout。在本來只有 first-phase 的時候,搜尋的 coverage 是大概 5x%,表示下的搜尋大概只處理了一半的資料,時間就不夠了,於是 Vespa 花了大概 2.1 秒左右後就放棄搜尋,把結果回傳了。而我們後來把邏輯移轉到 second-phase 之後,搜尋的 coverage 上升到 7x%,但整體搜尋時間反而上升到 3 秒。就是因為原本沒有 second-phase,所以被保留的 30% 時間(約 0.9 秒)完全不會使用它,但把邏輯移到 second-phase 以後,這 30% 時間就會被拿來用了,於是整體搜尋時間就變得更久了….(默)。
沒有留言:
張貼留言