這幾天經由 Vespa 的文章,讀到 OpenAI 在今年(2024 年)二月份的一篇在解說 MRL (Matryoshka Representation Learning) 的文章,看起來真的相當有趣!不過我並不是這個領域的專業,所以細部的內容我也沒有完全理解,這篇筆記大體只是我自己在應用上的基本理解。如果內容有誤也歡迎留言提醒。😇
MRL 是什麼?
Matryoshka doll 就是俄羅斯娃娃,而 Matryoshka Representation Learning 就是一種利用類似俄羅斯娃娃的特性(小的娃娃可以被裝進大的娃娃裡)做出來的 Embedding 方法,或者說是東西的表達手法。
那麼 MRL 跟其他 Embedding 方法最大的差異是什麼呢?就我目前的理解,最大的差異就是上述提到的,它具有俄羅斯娃娃的特性。具體來說,就是小的 Embedding 可以被放在大的 Embedding 裡,或者說是大的 Embedding 切割掉尾巴後,就幾乎等於是小的 Embedding。這個特性最主要的優勢,是在於我們可以不用針對不同維度的 Embedding 分別儲存不同的 Embedding,而是可以統一存一個 Embedding,在需要高維的時候使用 Embedding 裡的比較多內容、需要低維(更快更低成本)的時候則使用 Embedding 裡的一部份內容即可。

Vespa 與 MRL
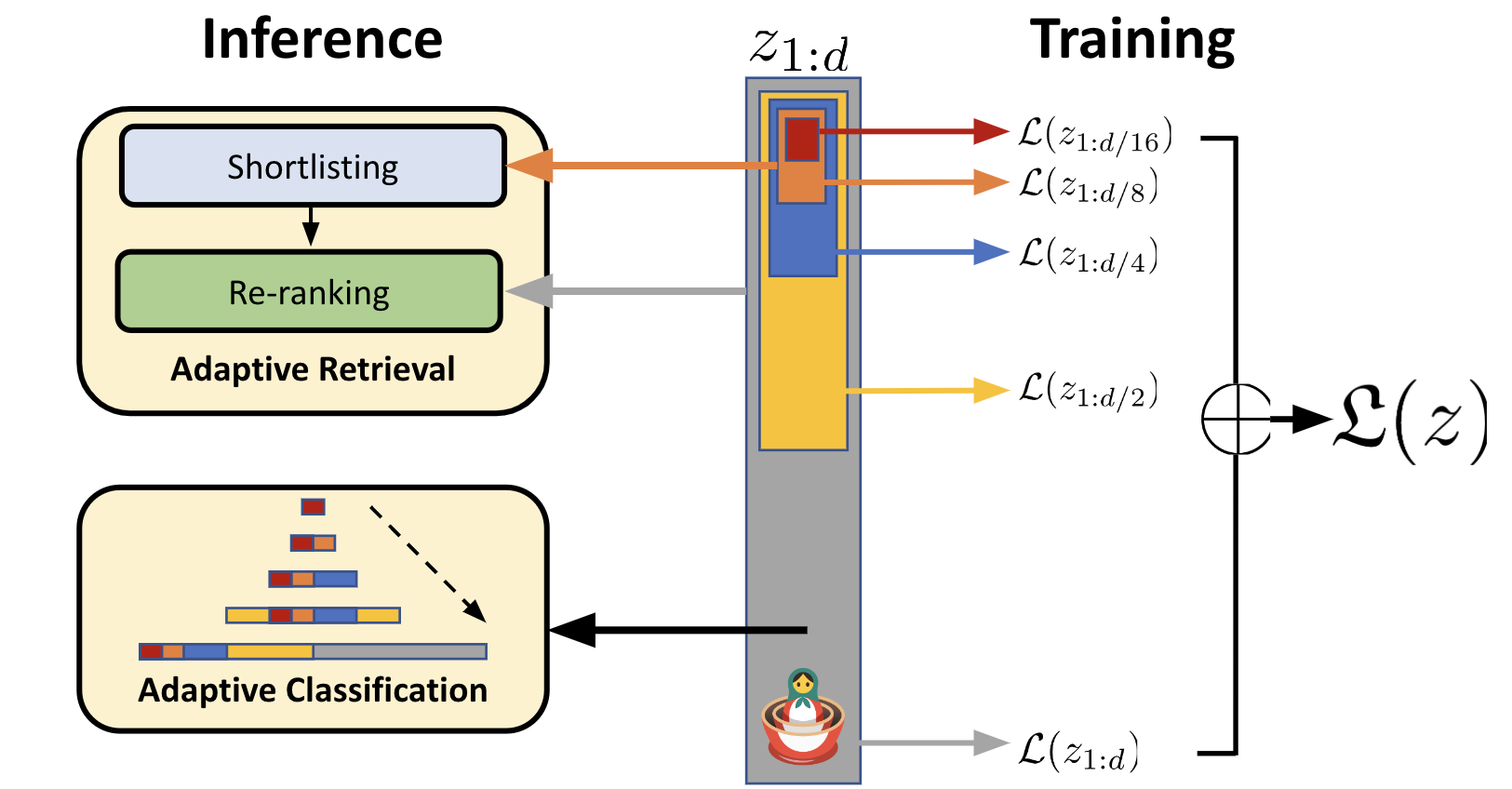
那麼回到 Vespa 的使用情境,MRL 可以帶來什麼效果呢?首先如同 MRL 文章在上圖中提到的,MRL 會很適合用在 multi-phase ranking 的場合,例如先使用低維度來找出較符合結果的 candidates,然後第二階段時再針對這些 candidates 使用高維度來做更精準的計算,找出最佳的結果。
在 Vespa 二月份的文章中,首先提到他們做了一點基本的實驗,發現 MRL 產生的 Embedding 在使用相同模型的情況下,產生 8-dimension 跟 3072-dimension 的 Embedding,確實中間只差了 scale 而已,本質上非常相似。接著他們實際實驗了把 3072-dimension 的 Embedding,裁掉尾巴並只留下最前面的 8-dimension,然後去跟一開始就用 8-dimension 產生的 Embedding 做 cosine similarity 比較,發現兩者的相似度高達 99.99999999999996% 。
最後,Vespa 團隊用 COVID-19 的資料集做了實際的搜尋實驗,分別有以下幾種:
- query_exact - 使用完整的 3072-dimension 並且不使用 ANN,也就是做最精準的語義搜尋。
- query_256 - 改為使用 256-dimension 的低維度 Embedding,同樣也不使用 ANN。
- query_256_ann - 使用 256-dimension 的低維度 Embedding,同時使用 ANN 做語義搜尋。
- query_rerank - 使用 256-dimension 的 Embedding 作為 1st-phase,選出 top 100,然後用 3072-dimension 作為 2nd-phase
結果如下:
run query_exact
.................................................. avg query time 2.7918 s
run query_256
.................................................. avg query time 0.3040 s
run query_256_ann
.................................................. avg query time 0.0252 s
run query_rerank
.................................................. avg query time 0.0310 s
query_exact ndcg_cut_10: 0.7870
query_256 ndcg_cut_10: 0.7574
query_256_ann ndcg_cut_10: 0.7552
query_rerank ndcg_cut_10: 0.7886
先看效能的部份,從 3072-dimensions 改為使用 256-dimensions 可以大幅加快搜尋速度,query time 只有原本的大約 11% 而已。而使用 ANN 的話,跟最開始的 query_exact 比較,甚至是只用了不到 1% 的時間!但效能提昇了,搜尋結果變差了多少呢?從 NDCG 來看,差異從 0.787 下降到 0.755 ,其實差異並沒有非常顯著。
如果我們直接比較 query_exact 跟 query_rerank 的話,得到的結果是 query time 是原本的 1.1% ,而 NDCG 幾乎一樣!從數據來看,MRL 的潛力真的相當大 😍