在 AWS 社群看到有趣的研究,在講述 AWS 的架構中如何讓 blast radius(爆炸的影響範圍)最小?或者說當服務節點出問題時,讓受到影響的客戶端影響最小。以客戶端來說,狀況的假設是客戶端發出 request,request 透過某種 Routing 送進後端的服務節點,不過因為某種原因 request 造成了服務節點崩潰。此時客戶端會繼續嘗試重發 request,然後如果 Routing 的機制沒有特別地設計的話,終究客戶端的 request 會一台一台地把所有後端服務節點全部弄掛,導致整個服務中斷。
推薦有時間的話可以在 Youtube 上看看 AWS re:Invent 2018 中 AWS 工程師 Peter Vosshall 的議程 [2]。AWS 在這個問題上,做了好幾個層級的處理,包含了物理隔離以及邏輯隔離。
Region Isolation
首先 AWS 所有的服務都有 Region,Region 和 Region 之間互相是完全不認識對方,也不會進行溝通。因此當某個 Region 遇到災難而整個損毀時,最多只影響到同個 Region 的其他使用者,而不會擴散到 AWS 的所有服務區域。
議程中 Peter 也有提到,因為 Region 內的服務本身是不會認知到其他 Region 的存在,因此對於像是 S3、DynamoDB Global Table 等等的跨區域服務來說,AWS 有額外的 Cross Region Orchestrator 在負責處理跨區域的需求。
Availability Zone Independence
AWS 的資料中心並非是在一個地區只會有一個,通常會有好多個,每個資料中心以高速光纖互相連接。一個 Availability Zone 可能包含一個或者多個資料中心,當發生某些災難導致資料中心損毀時,至少該地區的其他資料中心應該還存活著,能夠確保持續提供服務以及保障資料的安全性。
Cell-based Architecture

概念上,Cell-based Architecture 就像是在建造大型船艦時的隔離房間一樣。大型船艦一旦船體破洞,會導致整艘船被水灌入而沉沒,因此船艦在底部會隔離成很多間小房間,以確保當船體破洞的時候,水可以被隔離在某一小部份的小房間內,不會因此造成整艘船一起沉沒。用在系統上,在一個 Availability Zone 當中也可以切割成許多小的 cell,透過 cell router 決定 request 會進入哪個 cell,然後當 cell 被弄垮的時候,就只有垮掉的 cell 無法提供服務。
這裡會有許多比較細節的考量,例如 cell 的大小、cell router 的可靠性、遷移等等。
Shuffle Sharding
最後談到 AWS 使用的有趣的技巧:Shuffle Sharding。
假設我們有 8 個節點,然後有不同的客戶端來存取節點。其中以 diamond 代表的客戶端因為某個原因導致節點掛掉,並且 diamond 客戶端還會一直重試,進而陸續導致所有的節點都被 diamond 客戶端弄掛。此時的 blast radius 就是所有的客戶,因為最後所有人都無法存取服務。

當我們套用了 Cell-based Architecture 時,我們會依照某個規則決定讓不同的客戶端存取不同的 cell,因此 diamond 客戶端造成節點掛掉時,就算因為重試而導致的問題擴散,最多也只會擴散到整個 cell,從而保護了其他客戶端的存取不受影響。此時 blast radius 的範圍是總客戶數除以 cell 數目~。
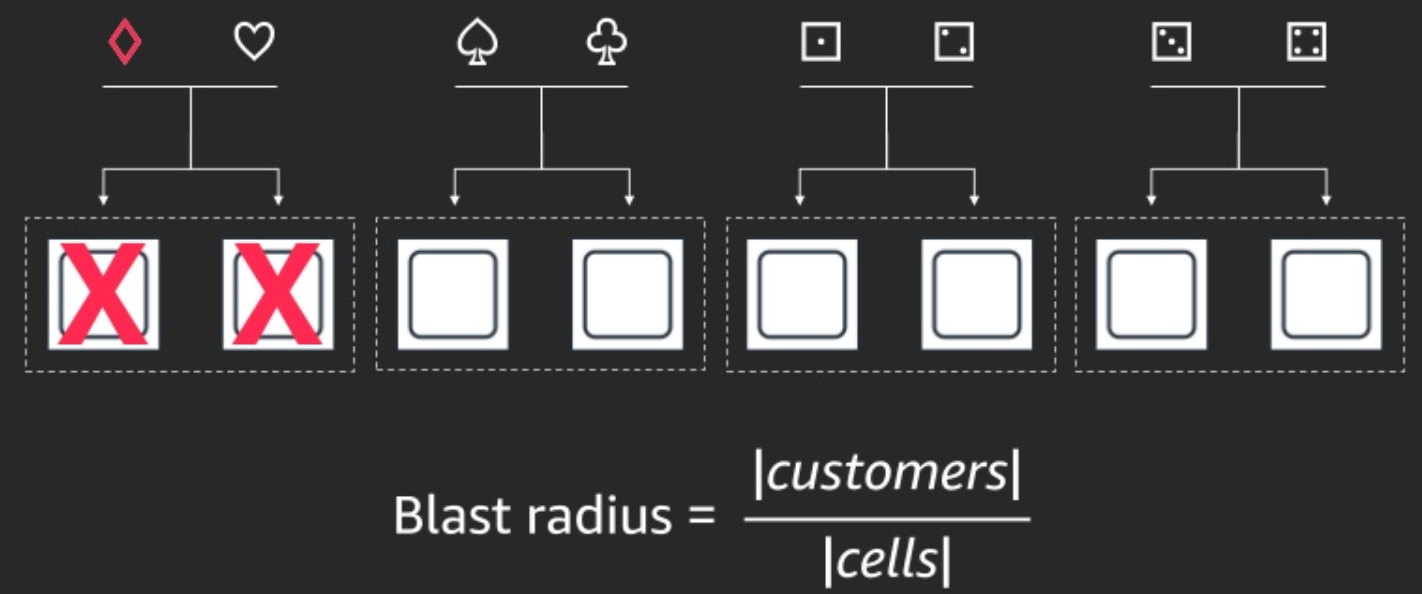
但再更進一步利用 Cell-based Architecture,AWS 導入了他們稱為 Shuffle Sharding 的機制。從名字可以看出,這是洗牌的概念,也就是 Sharding 的切割方式是用洗牌的形式給予,例如下圖中,diamond 客戶端會被分派到由 #1 和 #4 節點來服務;heart 客戶端則被分派到 #1 和 #2 節點來服務。然後同樣的事情發生了,diamond 客戶端把所有它存取的節點都弄掛了,也就是 #1 和 #4 節點都掛了。此時會受到影響的客戶是同樣會存取 #1 或者 #4 的 heart 和 club 客戶端。但由於它們個別都還會存取 #2 或 #6 節點,因此他們受到的實際影響,最多只有 request 感覺會變慢。例如 heart 客戶端可能發出一個 request 時被導去 #1 節點,此時因為 #1 節點掛掉了,所以它無法獲得正確的回應,接著它又重試一次,這次 request 被導去 #2 節點,它就順利拿到資料了。

在這樣的結構下,客戶端只有在剛好所有分配給它的節點全都掛掉的情況下,才會感受到服務中斷。而這也是能夠以數學定義機率的狀況。如果有 100 個節點、每個 Shard 被分配 5 個節點的話,所有的組合數會高達 75 million,讓節點掛掉造成影響的客戶數減少到只有 0.0000013%!
參考資料
- Shuffle Sharding: Massive and Magical Fault Isolation
- How AWS Minimizes the Blast Radius of Failures (ARC338) - AWS re:Invent 2018 (video) (slide)
- AWS Shuffle Sharding
沒有留言:
張貼留言